



产品简介
产品详情
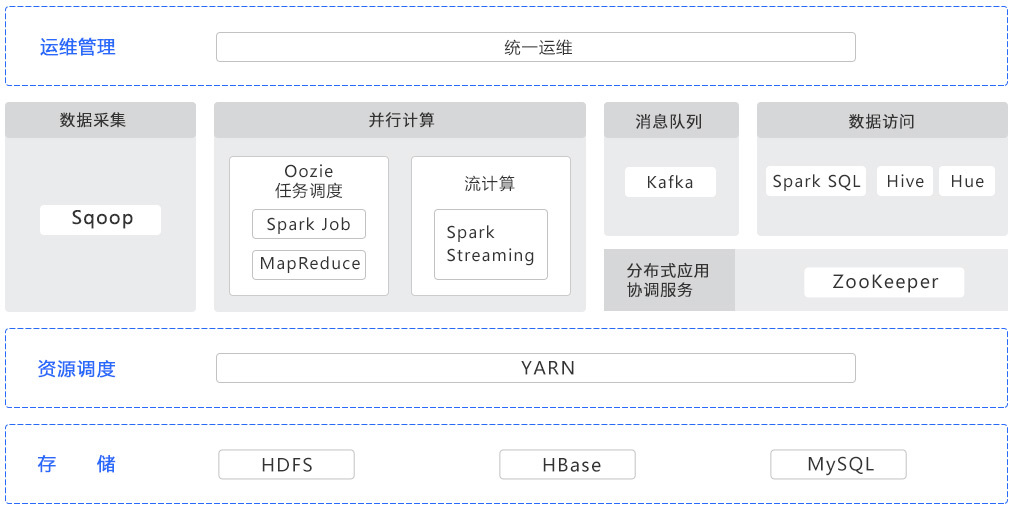
技术架构
核心功能
- 详情介绍
- 分布式数据存储
- 并行数据计算
- 统一资源调度
- 统一运维管理
-
- 商品名称: 大数据基础平台
- 商品编号: a01
大数据基础平台基于Hadoop、Spark等大数据平台框架构建,与大数据资源中心无缝对接,提供分布式数据存储、并行数据处理和统一管理维护等能力,有效应对DT时代数据爆发式增长的挑战。除满足海量结构化数据的存储分析需求外,平台还可以存储海量非结构化数据,例如图片、音频、视频、文本等,并且在数据资源汇聚整合后,提供分布式计算以及分析挖掘能力,为上层应用所需的数据服务提供保障。
技术架构
-
采用分布式文件系统HDFS实现非结构化数据存储,并支持多副本机制,提供高可用性及高并发访问服务特性。采用分布式数据库HBase解决传统关系型数据库面临海量结构化数据存在的高并发读写性能差、存储和查询效率低、扩展性差等问题,在容量、性能、成本方面满足大数据管理需求。

-
通过并行计算引擎MapReduce V2和Spark提供并行计算能力。MapReduce V2作业把输入的数据集切分为若干独立的数据块,由 Map任务以完全并行的方式处理,并通过YARN优化MapReduce中资源调度的问题。Spark是类MapReduce的通用并行计算框架,拥有类似MapReduce的并行处理模式,而且Spark任务的中间输出结果可以保存在内存中,计算效率更高,能更好的应用于数据挖掘与机器学习等需要多次迭代的算法,可以构建大型的、低延迟的数据分析应用。

-
大数据基础平台支持多种计算框架,可以通过资源调度组件YARN实现统一资源管理和调度。YARN能够接管所有资源管理的功能,兼容异构的计算框架,并且采用无差别的资源隔离方案,能够很好的克服MapReduce V1的可靠性差、扩展性差、资源利用率低、无法支持异构计算框架等缺点。

-
平台提供图形化界面供用户安装、部署和操作系统,并提供对集群节点的信息查看、运行状态查看以及节点的故障侦测和故障管理等相关管理功能,简化用户操作。平台发生业务故障或性能故障时,能自动产生告警,并针对告警日志进行集中收集和标准化处理,支持告警日志通过图形化界面导出,便于故障定位和管理。


开放架构
稳定可靠
性能优异
官网二维码